
How to Make RAG Systems More Memory-Efficient
If you’ve been working with RAG systems, you know the pain: its easy to gather lots of embeddings, and they need a lot of memory for storage and retrieval.
After spending quite some time researching this, I want to share some practical solutions we’ve found to make RAG systems more memory-efficient without killing their performance.
The Memory Headache
RAG is awesome. It helps LLMs access propiertary and up-to-date information and reduces hallucinations. And it’s very easy to accumulate lots and lots of embeddings.
But there’s a catch: storing those high-dimensional embeddings is a real memory hog. Just to give you an idea, if you want to store a million documents with OpenAI’s ada-002 embedding model, which has 1536-dimensional embeddings, you’re looking at about 6.1GB of RAM. Imagine the cloud costs for ONLY storing this data.
How Can We Fix This?
We dug deep into two main approaches to tackle this problem:
1. Quantization (or “How to Make Those Numbers Smaller”)
We tested various ways to represent our embeddings with fewer bits. Here’s what we found:
- float16/bfloat16: Cuts storage in half with barely any performance hit
- float8 variants: Now this is where it gets interesting - 4x smaller AND still performs great
- int8: Also 4x smaller, but not as good as float8. It also needs a calibration dataset
- binary: Goes all the way to 32x smaller, but performance takes a big hit
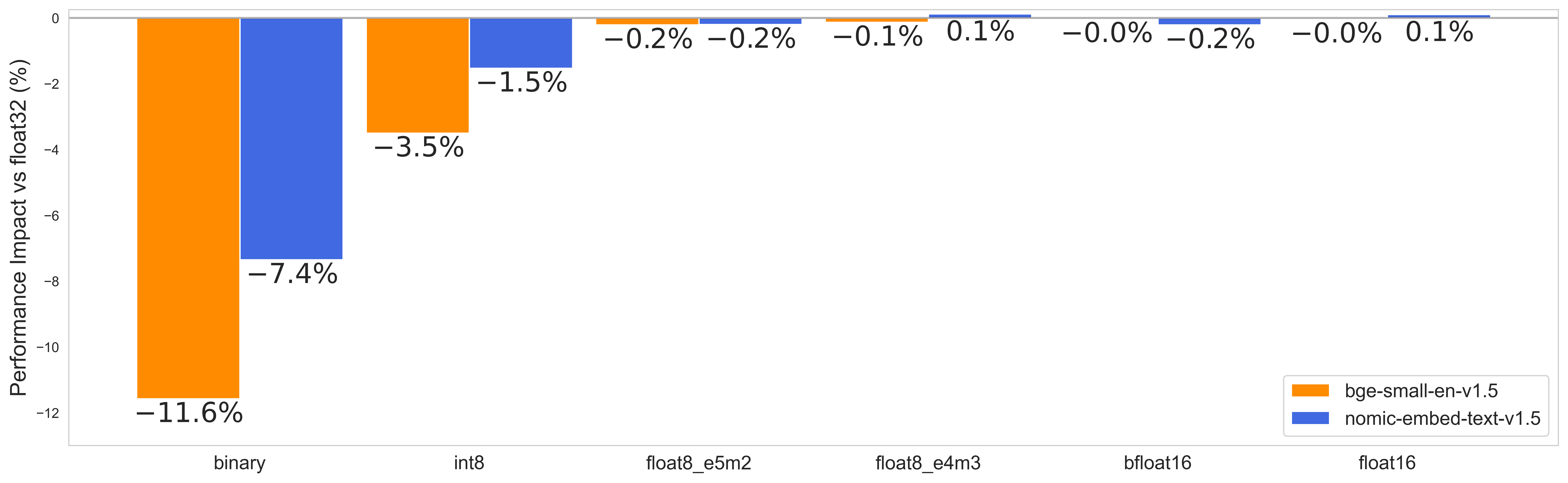 How different quantization methods affect performance - float8 is the sweet spot
How different quantization methods affect performance - float8 is the sweet spot
2. Dimensionality Reduction (or “Do We Really Need All Those Dimensions?”)
We tried several techniques to reduce the number of dimensions:
- PCA: The clear winner - simple and effective
- Kernel PCA: Works well but more complex (and slower) than regular PCA
- UMAP: Looks fancy on paper, but not terrible results for this use case
- Autoencoders: Kinda decent results but harder to implement than PCA
- Random Projections: Poor man’s PCA
The Best of Both Worlds
Here’s where it gets really interesting. By combining both approaches, we found some pretty cool solutions:
- Using float8 + PCA (mantaining 50% of dimensions) gives you 8x storage reduction while actually performing better than just using int8 (which only gives you 4x reduction). Better performance using less storage 🎯
- Bigger embedding models handle compression better
- float8 consistently played nicer with dimensionality reduction compared to int8 or binary
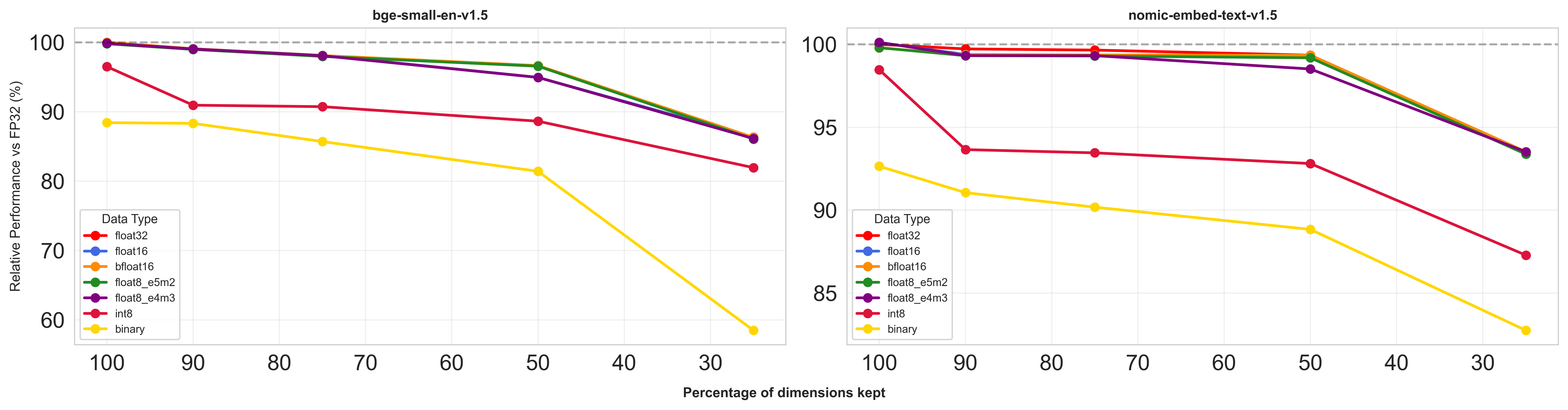 The magic happens when you combine both approaches
The magic happens when you combine both approaches
What Should You Use?
Based on our experiments, here’s what I recommend:
- Need moderate compression (up to 4x)? Just use float8 quantization
- Need more compression (4x-32x)? Combine float8 with PCA
- If you can choose your embedding model, go for a higher-dimensional one if you know you’ll need compression, they’ll perform better under dimensionality reduction.
How to Choose Your Configuration
We’ve developed a practical approach to help you choose the right setup:
- Figure out your memory budget
- Plot performance (e.g. MTEB Retrieval NDCG@10 average) vs storage needed for different options
- Pick the best performer that fits your memory constraints
Example for a 125k embeddings dataset. If your memory limit is 2000MB, you’d have to pick nomic-embed-text-v1.5 in float16 precision. For ~400MB memory limit, you’d have to choose bge-small-en-v1.5 in float8 precision.
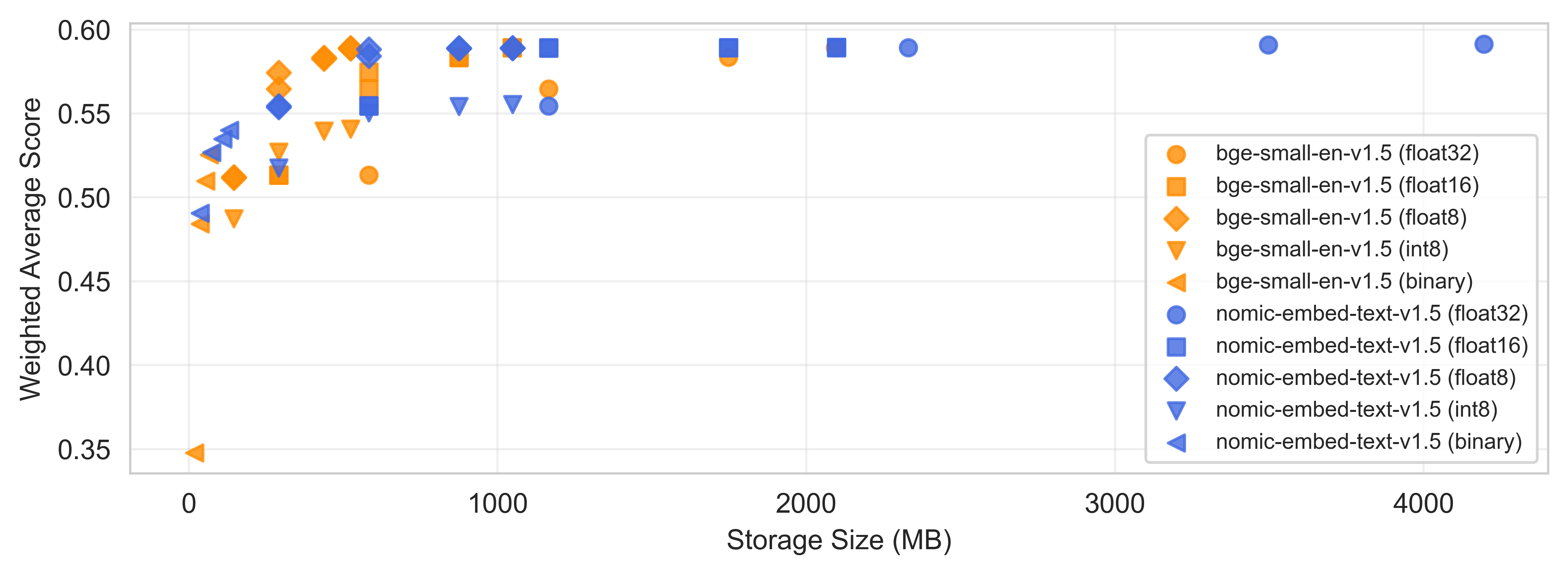 This visualization helps you pick the sweet spot for your needs
This visualization helps you pick the sweet spot for your needs
The cool thing about this approach is that it’s pretty flexible - you can adapt it based on your specific needs and constraints.
If you want to dig deeper into the technical details, check out our full paper: Optimization of embeddings storage for RAG systems using quantization and dimensionality reduction techniques.